身為軟體開發者,你有搞懂字元集、字元編碼、Unicode 等神秘的東西嗎?
作者表示連知名語言 PHP 都忽略字元編碼問題,非常歡樂地只支援8位元的字元集。

字元集
讓我們看看 ASCII 的編碼方式。
ASCII (American Standard Code for Information Interchange,美國標準資訊交換碼)
用一個位元組 (bite),即8個位元 (bit),來表示一個字元。
位元組的最高位統一規定為0,剩餘7位用來存儲數據。
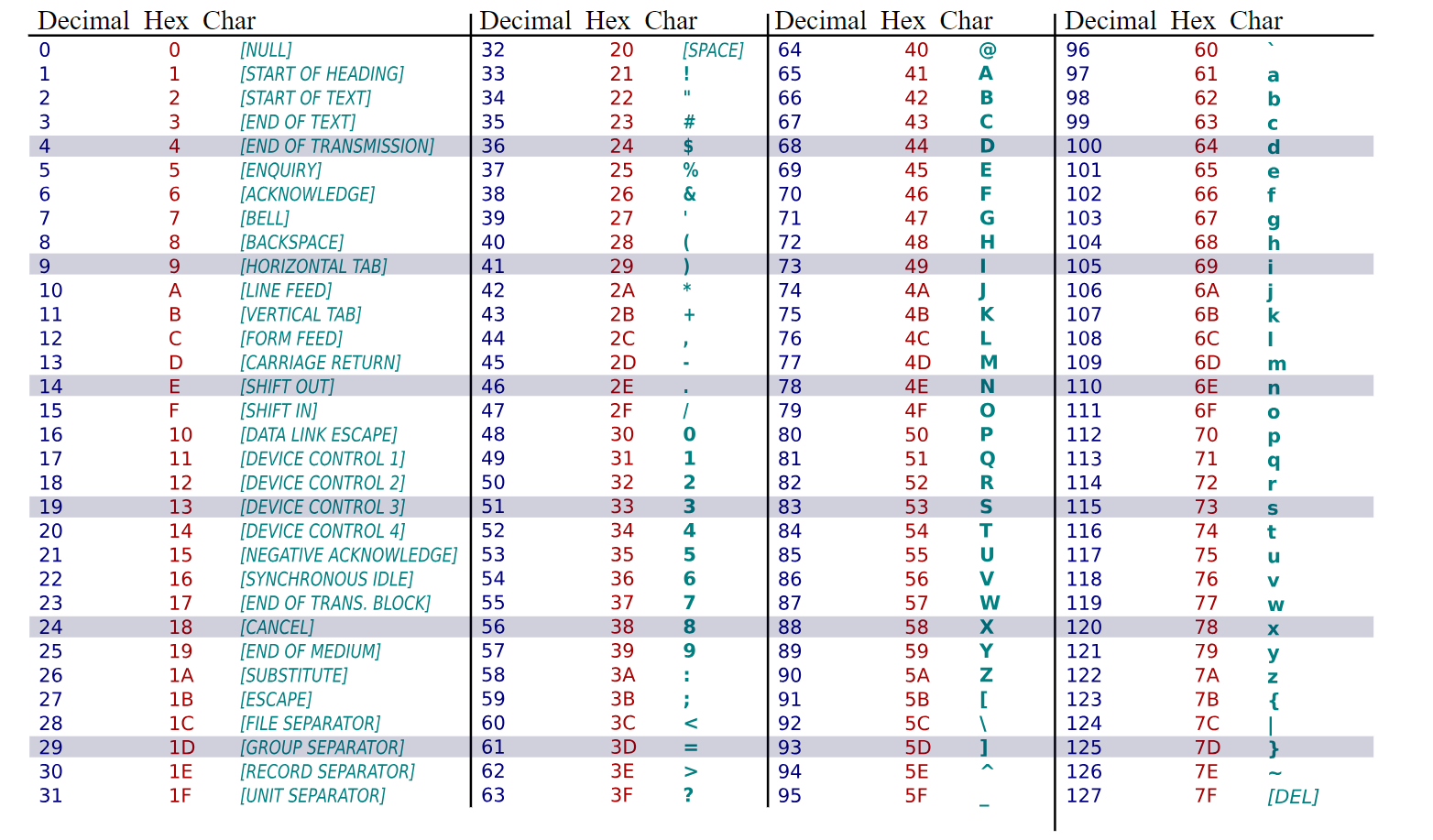
如果英文是你的母語,這一切都很好,沒什麼問題。
但由於一個 Byte 有8個位元,因此很多人開始思考利用 128-255 這段編碼範圍。
IBM-PC 用了一種名為 OEM 字元集的東西,提供了某些歐洲語言用的重音字母和一堆線條繪圖字元:水平線、垂直線、右邊有個小吊釣的水平線等等。

當 PC 開始賣到美國以外時,各種不同的 OEM 字元就被憑空創造出來,大家都把上面這128個字元拿來自己用。在俄文地區對於上面的 128 個字元甚至有多種不同的想法。
後來這段 OEM 終於在 ANSI (American National Standards Institute,美國國家標準協會) 中被固定下來。
大家都同意小於 128 的字元定義 (基本上和 ASCII 一致),但由 128 開始就有很多不同的處理方法,這些不同的系統就被稱為頁碼。
在亞洲地區中有些字母甚至要用到兩個位元組。當 Internet 興起時,在電腦間移動字串原本會是一個大麻煩,幸虧這時已經發明了 Unicode。
Unicode
Unicode 是個勇敢的嘗試,想用單一個字元集去涵括地球上所有的書寫系統。
有些人誤認為 Unicode 只是個 16 位元碼,裡頭每個字都要佔 16 位元,
所以總共有 65536 個字元。事實上這並不正確。
到目前為止,我們通常假設一個字母會對應到某些字元:
A -> 0100 0001
在 Unicode 的世界中,一個字母會對應到一個 code point 中。
即便在不同的語言中,A 的寫法可能會略有不同,
但 Unicode 協會的人已經花了 10 年搞定這些政治爭論。
Unicode 協會把所有字母系統中每一個觀念上的字母都分配一個魔術數字,
這個魔術數字就叫一個 code point 。
U+ 的意思是 Unicode,數字則是用十六進位表示。
例如 A 在 Unicode 中就是 U+0041 。
假設我們有個字串:Hello
用 Unicode 來表示的話,這個字串會對映到下面五個 code point:
1 | U+0048 U+0065 U+006C U+006C U+006F |
實際上也就是數字。不過我們還沒有提過要如何儲存到記憶體或在電郵訊息中表示。
字元編碼
這就是字元編碼上場的時刻了。
Unicode 編碼最初的想法導致了兩個位元組的迷思,簡單說就是把那些數字都存成兩個位元組。所以 Hello 變成
1 | 00 48 00 65 00 6C 00 6C 00 6F |
這樣對嗎?等一下!也有可能會是:
1 | 48 00 65 00 6C 00 6C 00 6F 00 |
因此有存成 high-endian 或 low-endian 模式,可以依據 CPU 用哪一種最快來決定。
由於美國人,看到的都是很少用到 U+00FF 以上 code point 的英文文字。
然後就有人發明了 UTF-8 這個絕佳的點子。
這樣做有個很巧妙的副作用,就是英文文字用 UTF-8 和用 ASCII會完全一樣,
所以美國人根本不會覺得有啥不對。只剩世界上其他地方的人得跳火圈。
因此上述的 Hello 可以寫成:
1 | 48 65 6C 6C 6F |
關於字元編碼最重要的一個事實
如果你完全不記得我剛說的東西,請至少記住一件超級重要的事實。
光有字串卻不知道編碼方式是不行的。
假設你有一個字串,不管是在記憶體或在檔案還是在電郵訊息裡,你都必須知道字串用的編碼方式,才能正確解譯出來並呈現給使用者。
以電子郵件來說,郵件表頭應該會有一個字串:
1 | Content-Type: text/plain; charset="UTF-8" |
如果是網頁的話,最原始的想法是在網頁之外,
再讓 web 伺服器傳回一個類似的 Content-Type http header。
不是放在 HTML 裡面,而是在傳 HTML 網頁之前先送的 header。
然而這樣會有問題,因為 web 伺服器不一定知道各個檔案的編碼方式,
所以也沒法傳出正確的 Content-Type header。
利用某些特別的 tag 把 HTML 檔案的 Content-Type 放在 HTML 檔案裡比較方便。
(幾乎所有編碼方式由 32 到 127 的字元都是一樣的,所以不需用到怪字母就能在 HTML 網頁取到這些資訊)
1 | <html> |
當 http header 或 meta tag 都找不到 Content-Type 時,
Internet Explorer 會做一件很有趣的事:
它會依據各位元組在各種常見語言編碼中出現的頻率,猜測網頁所用的語言及編碼方式。
課後練習
(Reference.)
ʕ •ᴥ•ʔ:算是徹底理解 Unicode 了。